
Q:你学的是java?
A:是的。大学学过。
Q: 那你说说java的关键字volatile
A: (心想:双重锁,单例模式,volatile。。。)volatile是用来防止指令重排和保证内存可见。
Q: 它的原理呢?
A:(TMD原理,肯定就是和虚拟机有关啦NND)只知道用,没有研究过这个。
Q:好吧,你还有什么要问的嘛?
A:你们这个岗位期待招聘什么样的人?
Q:嗯,高级一点的吧。
A:哦。没有了。
Q:那 回去等消息吧。
还原一下最近的一番对话,不过我实在是没记得当初java课上有讲过这个,知道指令重排和内存可见还是从某篇博客上看到的,也没有想过原理和为什么要这么做。那今天抽空理一理这个。现在想想应该是想通过其了解jvm相关的东西吧。
首先在多核处理器系统中,对一个变量的修改是存储在CPU缓存中的。
如果将一个域声明为volatile的,那么只要对这个域产生了写操作,那么所有的读操作都可以看到这个修改,即使使用了cpu缓存,该域会被立即写入到主存。而读取操作就发生在主存。这一过程产生的结果的的关系叫 Happened-Before
jvm 多线程下的内存模型
线程A 工作内存
|----- 内存读写操作 ---主内存
线程B 工作内存
用图来表示:
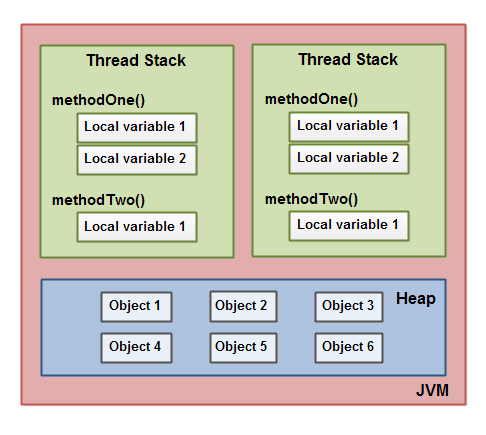
feature: 主内存被所有线程共享, 存储的是 heap 和 静态变量的 “本尊”
工作内存: 每一个线程都拥有自己的工作内存,存储了主存中的副本 ,可以理解为CPU高速缓存。 线程操作的是工作内存中的副本,线程之间不能直接操作别人的工作内存,通过主存进行。
这样问题就来了,如果没有同步锁,那么线程A 操作完还没有写入主存中,那么线程B即使后面运行,再去读取数据,但是获取到的是旧的。
Heap 中包含了创建的所有对象,不管是在哪个线程中创建的,这也包括原始类型的包装类
每一个线程都有自己的thread stack,线程执行同样的方法 ,其中的本地原始变量是存在各自的调用栈中且互相不可见,但是可以传递原始变量的拷贝给其它线程。
从硬件模型层面和JVM 内存模型来看,为什么在多线程的环境下 如果不用volatile会出现问题。
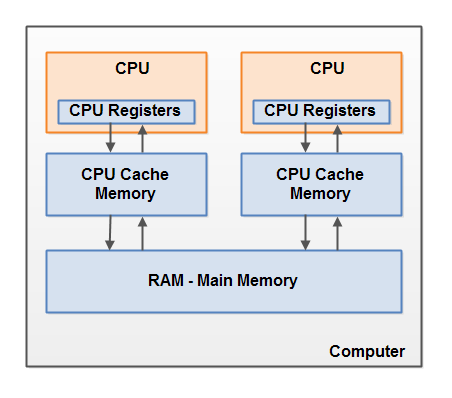
上图中,每一个CPU包含一系列寄存器。CPU 访问寄存器的速度>缓存>主存,因此,为了高效,当一个 CPU 需要读取主存时,它会将主存的部分读到 CPU 缓存中。它甚至可能将缓存中的部分内容读到它的内部寄存器中,然后在寄存器中执行操作。当 CPU 需要将结果写回到主存中去时,它会将内部寄存器的值刷新到缓存中,然后在某个时间点将值刷新回主存。而一个线程运行在不同的CPU上是可能的。
java 内存模型和硬件模型的关系

如图所示:硬件内存架构不区分java Thread Stack 和Heap ,在硬件层面,Stack 和Heap 都是位于主存,部分有时候在Cache 或者cpu 寄存器中表现。因此并不知道当前线程是在那个CPU ,heap是在缓存还是在主存,所以运行时不知道对方的变量的状态的。 感觉好乱。我们直接看它解决了什么问题吧
volatile 解决了什么问题?
一个线程在左边cpu 运行并将共享变量拷贝到它的cpu缓存,修改为2 ,这个改动对运行在右边的线程不可见,因为这个改动并没有刷回到主存。

解决了这个问题就是所谓保证了可见性。 The Keyword volatile can make sure a given variable is read directly from main memory , and always written back to main memory when updated.
指令重排
程序在执行的过程中 会对一些单线程操作的语句进行重新排序。有两个层面:
在虚拟机层面,为了尽可能减少内存操作速度远慢于CPU运行速度所带来的CPU空置的影响,虚拟机会按照自己的一些规则(这规则后面再叙述)将程序编写顺序打乱——即写在后面的代码在时间顺序上可能会先执行,而写在前面的代码会后执行——以尽可能充分地利用CPU
指令重排序是JVM为了优化指令,提高程序运行效率,在不影响单线程程序执行结果的前提下,尽可能地提高并行度。编译器、处理器也遵循这样一个目标。注意是单线程。多线程的情况下指令重排序就会给程序员带来问题。
不同的指令间可能存在数据依赖。比如下面计算圆的面积的语句:
[code lang=java]
double r = 2.3d;//(1)
double pi =3.1415926; //(2)
double area = pi* r * r; //(3)
area的计算依赖于r与pi两个变量的赋值指令。而r与pi无依赖关系。
[/code]
as-if-serial语义是指:不管如何重排序(编译器与处理器为了提高并行度),(单线程)程序的结果不能被改变。这是编译器、Runtime、处理器必须遵守的语义。
虽然,(1) – happensbefore -> (2),(2) – happens before -> (3),但是计算顺序(1)(2)(3)与(2)(1)(3) 对于r、pi、area变量的结果并无区别。编译器、Runtime在优化时可以根据情况重排序(1)与(2),而丝毫不影响程序的结果。
指令重排序包括编译器重排序和运行时重排序。
reference:
http://tutorials.jenkov.com/java-concurrency/java-memory-model.html
http://www.importnew.com/23535.html
https://en.wikipedia.org/wiki/Happened-before
抱歉,伤害了了你~
只能说是缘分哈 😊