
这是一个简单的不能再简单的问题,然而,就是这样简单的常见问题,往往会被忽视,从而给未来的某一天埋坑。
大多数编程语言都提供了built-in 截取字符串的方法。
比如 Python最为简单直观,比如从”Hello, World!” 中提取出 World 可以通过下标直接获取
text = "Hello, World!" substring = text[7:12] print(substring) #print World
在 JS 中,String 也提供
text = "Hello, World!" substring = text.substring(7,12) print(substring) //print 'World'
在 Android 中,Kotlin 和 Java 的 String 同样有类似的方法:
val text = "Hello, World!" val substring = text.substring(7,12) print(substring) //print 'World'
相信你也一定写过上面的代码,但是真的会如你的预期得到想要的结果吗?
一个字符串的下标,到底表示的是什么?
一个简单问题,什么是字符串? 英文我们叫String,其本意是用来串东西的细绳子。牛津词典解释如下:
long, thin material used for tying things together, made of several threads that have been twisted together; a piece of string used to fasten or pull something or keep something in place.
所以字符串表示就是一串字符咯, 这一点 Java官网也有定义( https://docs.oracle.com/javase/8/docs/api/?java/lang/String.html )。进而,我们可以理解为是对字符 Char(character) 的组合。即我们的下标可以理解为字符。
在 Android 中,我们字符串默认是使用 UTF-8 来编码的。 但是字符Char,则是 UTF-16来编码的。 官方定义: https://docs.oracle.com/javase/6/docs/api/java/lang/Character.html
这也就是说为什么”abcdefg” 当 index 为 0 得到Char, a。 1得到 b。
一个英文字母 UTF-8编码下占用一个字节,如果是汉字,UTF-8 编码的“我爱北京天安门” ,下标指代的字符是不是和上面英文一样呢?(0代表 我,1 代表爱)
答案是: 是的。为什么?通过上面科普了解到,虽然一个汉字在 UTF-8 中占用了三个字节, 大于一个 char 所占用的 2 个字节,但是为什么还能和只占一个字节的英文产生一样的效果? 因为这个char是 UTF-16编码的文本,占用两个字节, 大部分汉字,在 UTF-16 编码的情况下只占两个字节,因此可以以 char 来进行分割得到一个完整的汉字。
上面的每一个汉字和字母其实都对应一个unicode码点(code point)。 而我们代码中的索引指的是一个String 串下标 index 是 char 的位置position。 两者并不对应,这一点不能理解错了。
所以一个 char 能代表一个汉字吗?,答案是不一定,举个例子
“𰌂” ,它的长度就是 2,需要两个 char 才能代表字符
val s="𰌂" print(s.length)//输出 2

如何解决呢?让 index 变成我们理解的 index 呢。
针对上面情况,处理自己手写代码以外,在 Java中 String 类有一个叫offsetByCodePoints 的方法,接收一个两个参数,第一个是 index,也就是char 的 index,如果指定为 0 则从第一个 char 开始。codePointOffset 就是我们理解的那个字符的index拉,通过它我们就能拿到我们需要的字符的对应到 char 的 index。
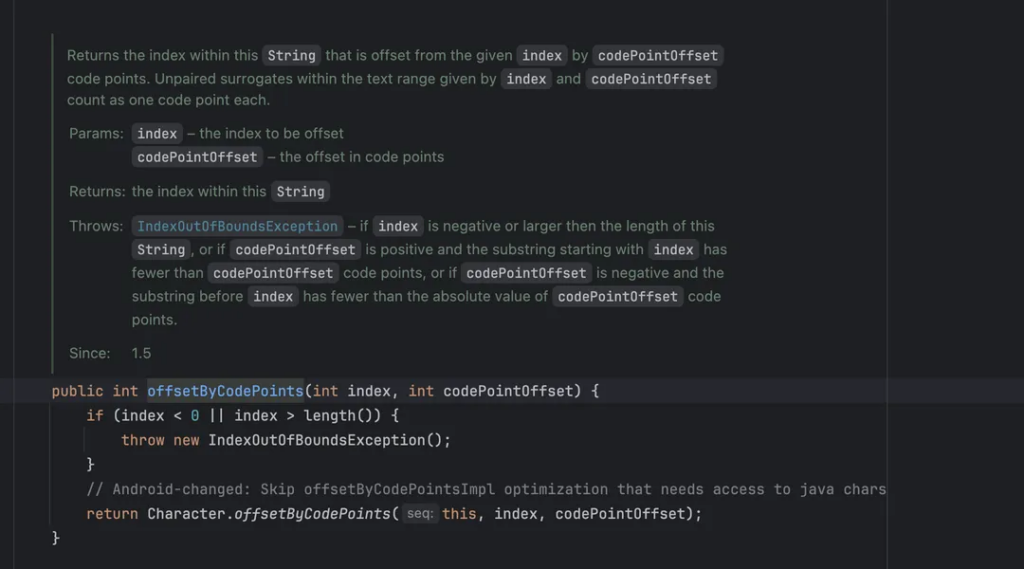
举个例子方便理解,我们通过 offset 设置为我们所理解的字符的 index 为 2,则输出“吃”
val s="𰌂好吃"
print("s:"+s[s.offsetByCodePoints(0,2)])// 输出 s:吃
当我们要从”𰌂好吃” 截取子串”好吃”的时候,我们可以通过转换索引得到正确的 char 的 index,再进行截取。
val t="𰌂好吃"
val key="好吃"
val index = t.offsetByCodePoints(0,1)// 假设我们已知好的 index 为 1
print("s:"+t.substring(index, index+key.length))//输出: s:好吃
看到这里,你应该明白了 char 的 index 和码点(字符)的 index 应该不是同一个概念了吧。
除了汉字之外,另一类常见的字符也有可能出现截断失败,那就是 emoji ,emoji出现截断失败的情况甚至远比截断汉字更常见。
emoji表情在字符串中到底是什么?
首先,emoji 是怎么表达的,当然也是通过码点,但是,它有可能是一个codepoint,也有可能是多个codepoints,因为它的字符集是不断在扩充的。到现V16版本在已经有 3790个了 传送门( https://unicode.org/emoji/charts/emoji-counts.html)
一些简单的 emoji 由单一的 codepoint 表示😀 (笑脸) 的 codepoint 是 U+1F600。
一些复杂的 emoji 由多个 codepoint 组合而成。例如:👨👩👧👦 (家庭) 是由多个 codepoint 组合而成的:U+1F468 (男人) + U+200D (ZWJ) + U+1F469 (女人) + U+200D (ZWJ) + U+1F467 (女孩) + U+200D (ZWJ) + U+1F466 (男孩)。
这一类叫做ZWJ Emoji,ZWJ 是 Zero Width Joiner(零宽连接符)的缩写,Unicode 中的 codepoint 是 U+200D。ZWJ 用于将多个字符连接在一起,形成一个新的复合 emoji。ZWJ emoji 是通过将多个独立的 emoji 字符用 ZWJ 连接符连接起来,形成一个新的、更复杂的图形。这样我们就能不断扩充表情了🤣🤣🤣
那这样的话上面代码就看不出有几个“我们理解的”index 了,因为你不知道这个 emoji 占用了几个 codepoint,从而使用 codepoint 去切分 emoji,如果遇到的是 ZWJ emoji 就会将 emoji 截断了,不符合预期啊。
而且,emoji 占用几个 codepoint 甚至连系统都不一定知道,因为这是一个动态可拓展的,有些 emoji 低版本的系统上就是不能正常显示的。我们在一些编辑器中对这种 emoji进行删除操作时还会出现变成另外一个 或者多个emoji 的情况

既然系统认不认识,只有系统才知道。
那没有解了么?
一个容易想到的方法是通过 emoji 的规律使用正则匹配,但是 emoji 是不断迭代的,谁能保证 V17 V18后面不会新增新的组合呢.
或者寻求另外的解决方案。比如本地将 emoji 列表全部记录下来使用映射来判断当然也是一种方法,但是这样要求app 额外占用了内存空间。
以上两种方法效率上来说都不高。
看看有有哪些现成的可以用吧。查阅了一些资料后,BreakIterator 是一个用于文本边界分析的类,它可以识别文本中的边界位置,例如单词边界,应该可以正确的划分 emoji 吧。
通过BreakIterator.getCharacterInstance() 可以拿到迭代器Iterator,进一步迭代文本。
代码如下:
fun main() {
val t= "𰌂👨👨👧👦"
count(t)
}
fun count(s:String){
val breakIterator = BreakIterator.getCharacterInstance()
breakIterator.setText(s)
var currentIndex = breakIterator.first()
val lastIndex = breakIterator.last()
while (currentIndex < lastIndex) {
val next = breakIterator.following(currentIndex)
val currentStr = s.subSequence(currentIndex, next)
Log.d(TAG, "current: $currentStr")
currentIndex=next
}
}
在intellij 中实践发现并不好使。输出如下

最开始怀疑是 getCharacterInstance 的问题,换成getWordInstance 依旧不行,只是忽略掉了U+200D, 该切割的还是
但是在 Android 平台试验却能够正确的处理!

查阅官方文档 https://developer.android.com/reference/kotlin/android/icu/text/BreakIterator 发现,Android 系统中修改了BreakIterator 的实现, 使用了同名的 android.icu.text.BreakIterator,而且使用的是纯 Native 实现,那不比上面的方法效率高?
官方并对getCharacterInstance的用法给出了说明,此 Character 非彼Character

难道 Java 真的不行吗? 其实是支持的,但是因为我使用的是SDK 版本是 17, 更换成 JDK 20+,表现也是一致的了。。

总结
所以正确的姿势截取可以如下参考( Android or JDK20+):
fun main() {
val t = "𰌂👨👨👧👦abc"
println(cutFirst(t, 4))//输出 𰌂👨👨👧👦ab
}
fun cutFirst(s: String, count: Int): String {
val breakIterator = BreakIterator.getCharacterInstance()
breakIterator.setText(s)
var currentIndex = breakIterator.first()
val sb = StringBuilder()
var total = 0
while (currentIndex != BreakIterator.DONE && total < count) {
val nextIndex = breakIterator.next()
if (nextIndex == BreakIterator.DONE) break
sb.append(s, currentIndex, nextIndex)
currentIndex = nextIndex
total++
}
return sb.toString()
}
以后产品/设计同学说,这个展示区域超过 x个字符则截取,你应该不会无脑写下如下代码了吧
val substring = text.substring(0,x)
虽然看起来是一个很简单的需求,考虑到ugc 内容后,可能有许许多多意想不到的情况出现。多语言比如印地语,RTL等其他的展现方式都可能受到影响。