
接着昨天的问题
-HashMap 用的多吗?
– 嗯挺多的
– 能说说其原理吗?
– HashMap 是一种数据结构,我们可以通过Key 来存储一些value。 利用Key的HashCode 做为内存地址,以便于很快的查找到对应的Value。
– 什么内存地址?
– 就是java虚拟机中的内存啊,不知道是堆还是栈
– 啊???(心里活动:妈勒个蛋,一本正经的胡说八道)好我们不说这个,那你说到HashCode ,请问HashCode 有可能发生碰撞吗?
– 当然会(hashCode 返回的也就是int 行,最多也就是2的32次方个。总是有限的嘛,而我们的对象可以无限制创建,虽然我还没有对象)
– 那HashMap是如何解决这个问题的呢。
– 额,这个几率会很小吧,可能需要我们重写一下key的hashCode,因为Key 也是Object类的子类吧。所以可以重写,额。。。
– 。。。。
承认,没看过HashMap 源码,我的错。我应该直接说没看过的。尴尬。
那今天来具体看一下 。
说点简单的,HashMap 怎么存储我们的 Key Value,从put 方法开始跟踪。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
一个hash 函数。(这个有兴趣可以再看看是怎么算的,我写完这个再去看看) 算出了Hash.
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
-----
确实,Key Value 等信息作为一个Node 放到了一个 Node的数组里面。如果出现我们上面说的那种情况,key 不一样,但是其hash 一致的情况下,(假设之前存在了一健值对) 这时候我们去看 上述代码中的 p,通过一个for循环找到Node的链表的结尾。然后把我们的新的Node挂到上面这时候看起来想这个样子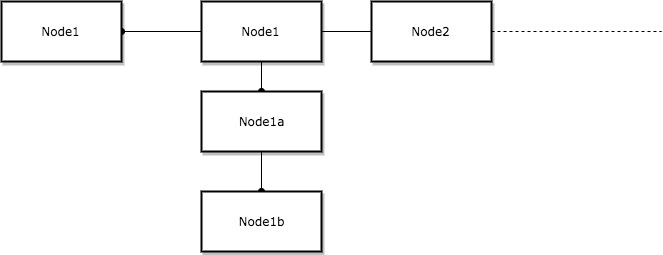
我们可以看到横排就是数组(忽略前面Node1),竖排就是同一个hashCode 对应的不同Node。
Node 是什么 ,我们可以看到其实就是对Key Value的一个封装,实现了Entry接口,同时Node 也是一个链表的节点。因此,可以无限拓展下去。
好了,很直观的知道了HashMap中的数据结构。
那么 问题来了 HashMap 如何查找到我们的Value 的呢?我先猜想一下
第一步,还是计算key的hash
第二步,然后用hash 去遍历Node 数组,对比其Node 中存储的hash是否一致
修正一下,这里并不是遍历了数组,而是直接用hashcode 和数组的长度-1 进行了 &运算, 时间复杂度为O(1) ,遍历的话时间复杂度久违O(n)了
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
第三步, 发现数组中存在,然后把Node 中的Key Value return 出来
但是问题来了 hashCode相同。也就是会有一些情况是上图中竖下来的节点链表,她们的hash都是一致的啊,怎么办?看源码。点开get方法
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
代码很短, 关键代码
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
/////
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
////
看到了没,因为key的hash相同,因此在竖直方向变量链表直接用了key 本身来判断 不可能出现key相同 hashCode 不同的情况,所以一个key 只能对应一个value。 这里注意,除了== 判断,而且用了 equal 去判断, 也就是说假如我们可以修改了equal方法,将会导致 不同的key(有可能hash相同),对应同一个Value,这样就不安全了,因此,我们一般用String 作为key 因为String 是final的。我们没法重写其equal 方法,就是这个原因。
这其中还有几个问题。我懒得写了,大家自己想想,鼓励在下面留言去讨论
1 数组存储Node ,而数组容量一开始就是确定的,那如何动态添加到数组的呢? 关键词 load factor
2 为什么要用数组去存储,直接用链表或者树不行吗?
3 代码中TreeNode 出现了好多次,那是什么?
下面分析View的绘制流程。。。。 不要以为我看不懂源码。MMP
hi 老朋友,好久没联系了,我今天粗略的把你的博客都简单过了一遍,感觉这样才真正的认识了你呢,我觉着我应该也有一个写日记的习惯。
已经是年更博主了,记日记推荐用Notion
不仅是年更,而且是两年更(biennial) 不是biannual