都2024年了,苹果系统内部还没有解决.

当右侧icon较多时,默认分辨率的屏幕很容易当icon超过10个时多余的icon 挤到 notch区域,然后怎么样都无法点到了。
Continue reading “快速解决Mac OS 被顶部图标摄像头挡住的问题。Quickly fix the Camera area covered the menu icon on MacOS”
做一个有趣的人
互联网上转载的有趣的,无聊的,手贱的。。。。。
都2024年了,苹果系统内部还没有解决.
当右侧icon较多时,默认分辨率的屏幕很容易当icon超过10个时多余的icon 挤到 notch区域,然后怎么样都无法点到了。
Continue reading “快速解决Mac OS 被顶部图标摄像头挡住的问题。Quickly fix the Camera area covered the menu icon on MacOS”最近需求需要接入地图SDK,本想腾讯地图确实不给力,想看看竞品做的如何,发现高德的SDK更烂。
首先是sdk还停留在十年前,使用jar包方式集成。需要拷贝一大坨jar包到工程项目中。
后来下载了demo,一堆报错,2024年了,demo中的gradle版本还是4.6版本,gradle tool 版本更是3.0,与java11 都不兼容。
解决完工程结构后,发现运行竟然报错。报错的原因是变更了jar包中类的处理。
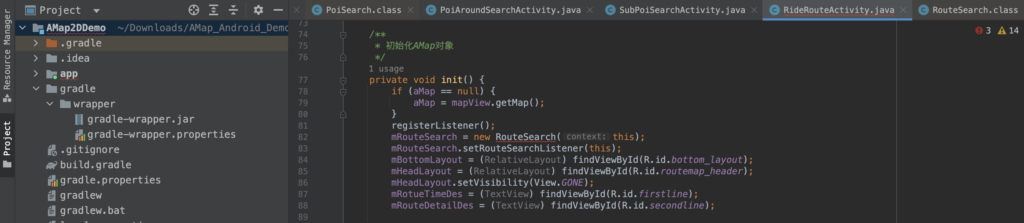
大量的类在构造的时候需要Catch住?真的是毁了三观。
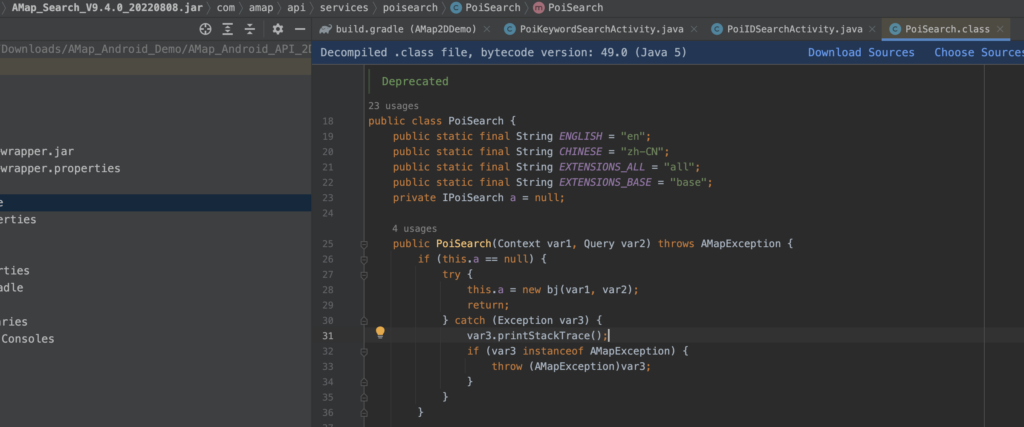
作为一个知名的地图开放平台,显得太不专业了。
年前把工作定下来,虽然有些小插曲,但是看淡就好。 但也收获了不少,主要是结合自己之前面试别人,这次从求职者的角度重新审视了整个过程,发现之前存在的一些问题。
见过一系列招聘者,有各种类型的,有外包公司,小型创业公司,中型公司,大型公司,都有接触过,各有各的pros and cons
Continue reading “求职者,招聘者”
事情是这样的,我这个笔记本的ssd硬盘只有256G,虽然目前还够用,但难保我这种不善于整理文件的人来说,迟早会全部占满的, 于是我想通过网盘分担一部分的存储,于是想到了云盘,后来发现好像只有百度有mac版本的同步盘,下载安装后,在本地选择了一个目录作为同步目录,结果,它居然把网盘上所有的文件都同步下来了。这可不是我想要的。
我觉得云盘同步盘应该是像tortoise那样作为一个插件,可以直接对目录同步,微云的那个作为一个单独软件(mac版本)让用户上传下载,真心还是一个上个时代的产品,除了传大文件方便点,对于操作目录还是不够方便, 目前很多云盘提供的网络存储都是好几T的空间了,虽然自己个人资料加起来都没有几个T,个人电脑的硬盘也能够达到T级别,可是对于本地存储空间不大的ssd的笔记本,和移动设备还是需要更多的存储空间, 云盘服务提供的同步盘能够让用户感觉自己的资料放在本地,目前看的百度云盘的同步盘功能是在服务端和本地同时存了一份,如果换一台电脑,比如我到台式机上去,安装同步盘,用同一个帐号登陆,同样会把所有的文件同步下来,可是如果有好几个T的资料呢?我并不需要把所有的文件都同步下来,比如有很多视频资料可以在线播放,何必都要下载下来占本地的资源呢?我希望只在本地留一个镜像文件,如果要同步可以自己手动同步,也可以设置哪些文件或者目录一旦变更就自动同步,这一点对自己写的文档或者代码,可以在切换不同的电脑时感觉会很方便。